Nodes
Kubernetes runs your workload by placing containers into Pods to run on Nodes. A node may be a virtual or physical machine, depending on the cluster. Each node is managed by the control plane and contains the services necessary to run Pods.
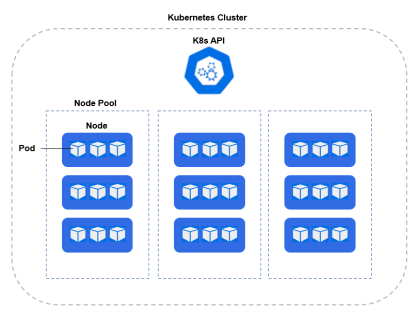
Typically you have several nodes in a cluster; in a learning or resource-limited environment, you might have only one node.
The components on a node include the kubelet, a container runtime, and the kube-proxy.
Management
There are two main ways to have Nodes added to the API server:
- The kubelet on a node self-registers to the control plane
- You (or another human user) manually add a Node object
After you create a Node object, or the kubelet on a node self-registers, the control plane checks whether the new Node object is valid. For example, if you try to create a Node from the following JSON manifest:
{
"kind": "Node",
"apiVersion": "v1",
"metadata": {
"name": "10.240.79.157",
"labels": {
"name": "my-first-k8s-node"
}
}
}
Kubernetes creates a Node object internally (the representation). Kubernetes checks that a kubelet has registered to the API server that matches the metadata.name field of the Node. If the node is healthy (i.e. all necessary services are running), then it is eligible to run a Pod. Otherwise, that node is ignored for any cluster activity until it becomes healthy.
Node name uniqueness
The name identifies a Node. Two Nodes cannot have the same name at the same time. Kubernetes also assumes that a resource with the same name is the same object. In case of a Node, it is implicitly assumed that an instance using the same name will have the same state (e.g. network settings, root disk contents) and attributes like node labels. This may lead to inconsistencies if an instance was modified without changing its name. If the Node needs to be replaced or updated significantly, the existing Node object needs to be removed from API server first and re-added after the update.
Node status
A Node’s status contains the following information:
Addresses
Conditions
Capacity and Allocatable
Info
You can use kubectl to view a Node’s status and other details:
kubectl describe node <insert-node-name-here>
Resource capacity tracking
Node objects track information about the Node’s resource capacity: for example, the amount of memory available and the number of CPUs. Nodes that self register report their capacity during registration. If you manually add a Node, then you need to set the node’s capacity information when you add it.
The Kubernetes scheduler ensures that there are enough resources for all the Pods on a Node. The scheduler checks that the sum of the requests of containers on the node is no greater than the node’s capacity. That sum of requests includes all containers managed by the kubelet, but excludes any containers started directly by the container runtime, and also excludes any processes running outside of the kubelet’s control.